Fitting Bayesian Distributed Lag Non-Linear Models with inlabru
Methods
Author
Olivier Supplisson
Published
April 26, 2026
Distributed lag non-linear models (DLNMs) are useful when an exposure can affect the response both non-linearly and with a delay. A common example is environmental epidemiology: today’s health outcome may depend on today’s temperature, yesterday’s temperature, and temperatures several days before, with a response curve that is not linear in temperature and not constant over lags.
The original DLNM formulation was described in Gasparrini et al.’s article, Distributed lag non-linear models, https://pmc.ncbi.nlm.nih.gov/articles/PMC2998707/. The standard R implementation is the dlnm package, described in the Journal of Statistical Software article Distributed Lag Linear and Non-Linear Models in R: The Package dlnm, https://www.jstatsoft.org/v43/i08/. Here I used dlnm::crossbasis() to build the cross-basis, then fitted the resulting Bayesian latent Gaussian model with inlabru.
The bdlnm package provides a convenient wrapper for fitting Bayesian DLNMs with R-INLA, as described here.
Instead of using a dedicated wrapper, some users may prefer to fit these models directly with inlabru. The goal here was to show how to turn a DLNM into:
a matrix-based model component,
a smooth Gaussian Markov random field prior on the tensor-product coefficients,
an inlabru component fitted through generic3 and bm_matrix().
Model
Let \(Y_t\) be a count response and let \(x_t\) be an exposure observed over time. A DLNM with maximum lag \(L\) can be written as
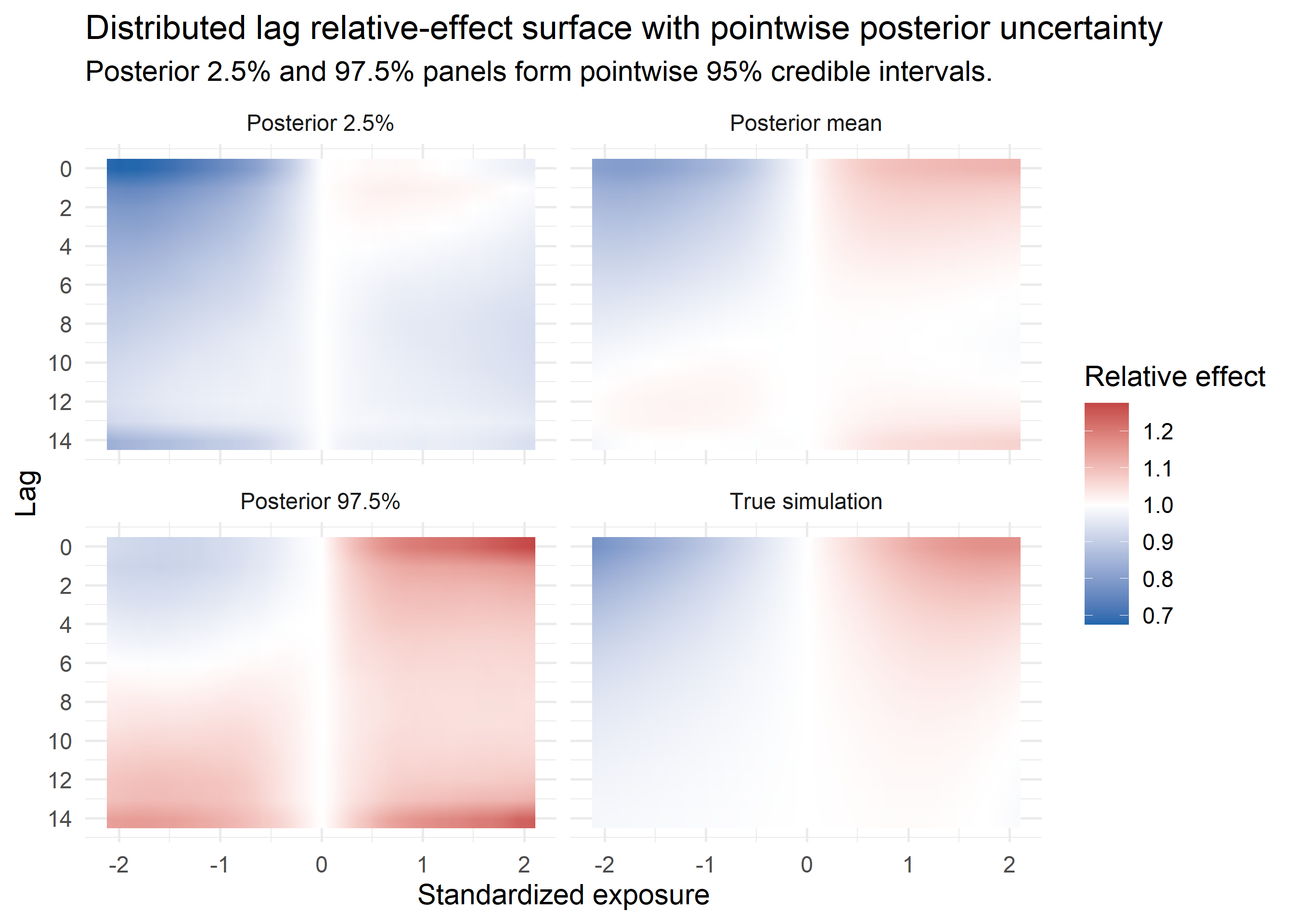
The surface \(f(x,\ell)\) is the object of interest. It encodes the exposure-response relationship along \(x\) and the delayed effect pattern along the lag dimension \(\ell\).
In the fitted example, I approximated this surface with a tensor-product basis:
so the distributed-lag contribution is simply \(A_t \theta\).
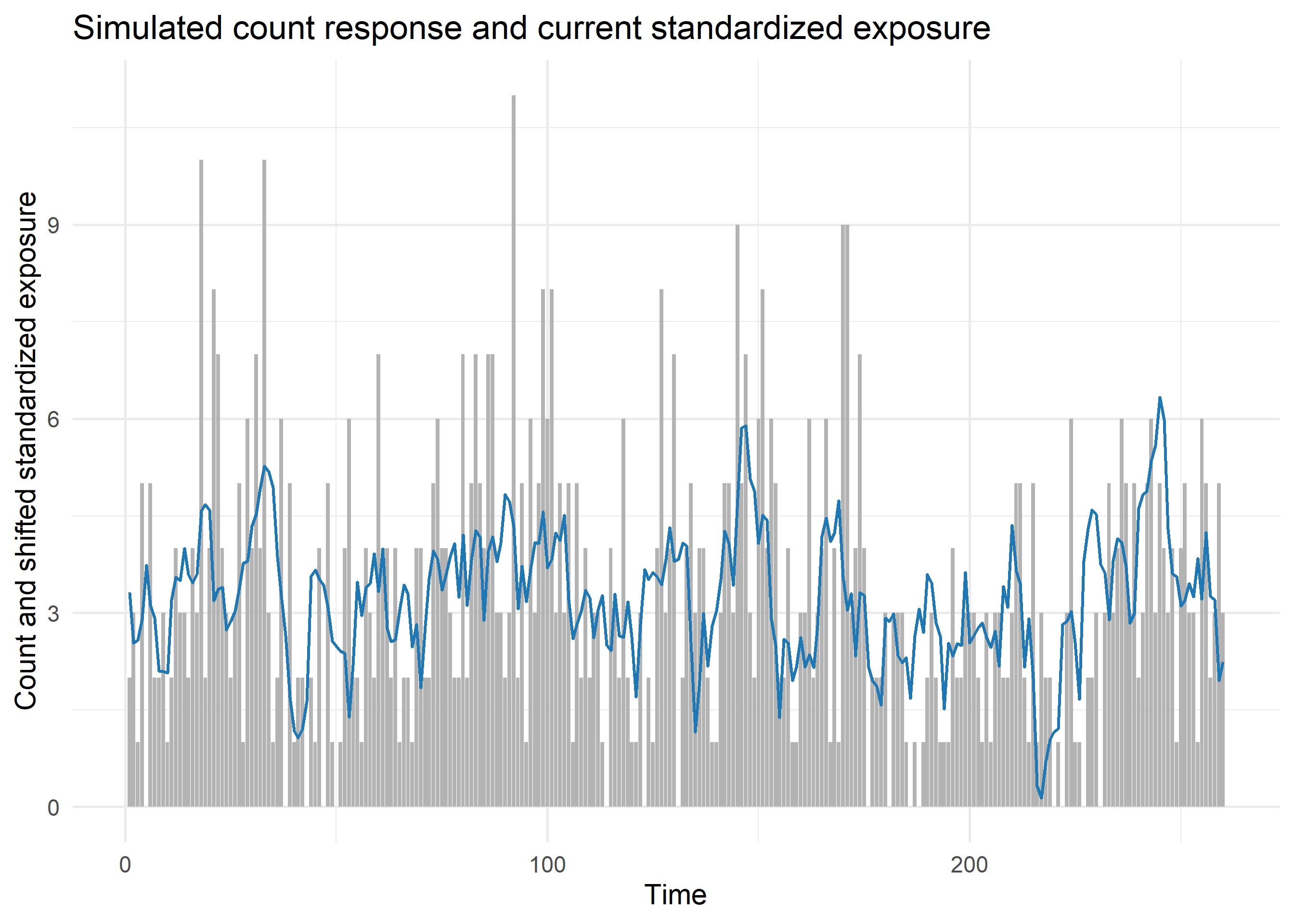
Simulated data
Let us now simulate some data so that the fitted surface could be compared with the truth. The exposure was autocorrelated, because lagged exposures are rarely independent in realistic time series. After simulation, I centred and scaled the exposure, so negative exposure values meant below-average exposure values rather than physically negative exposures. I set the baseline high enough for the latent-intensity comparison to be meaningful: with a much lower intercept, the response would have contained too many zeros to recover the latent intensity cleanly from one count series.
I built the cross-basis from a spline basis along the exposure axis and a spline basis along the lag axis. To do so, I used dlnm::crossbasis() directly, with one row per observed exposure history. The example used ten basis functions in each direction, so the tensor basis was fairly flexible while the smoothing prior still controlled roughness. Its columns were ordered in exposure-basis blocks, with the lag-basis index varying fastest:
Column centering separated the intercept from the cross-basis contribution. Without it, the intercept and parts of the spline surface could compete for the same constant shift.
Tensor-product prior
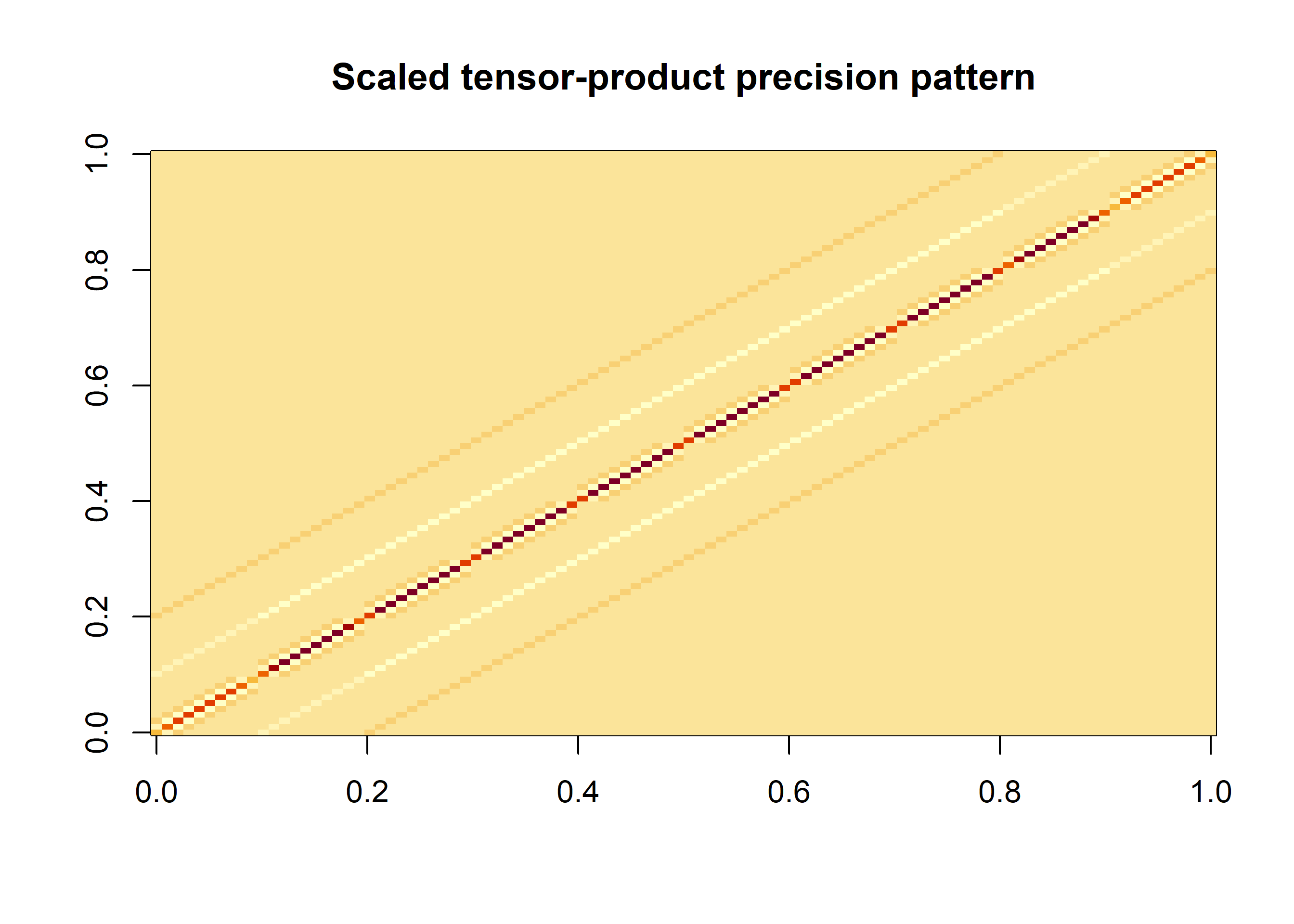
The 10 by 10 cross-basis introduced 100 latent coefficients. Without a structured prior, those coefficients could vary almost independently, which would make the surface too sensitive to Poisson noise and to sparsely observed exposure-lag combinations. The regularisation therefore had to work in both directions of the tensor product: neighbouring exposure-basis coefficients should be similar for a fixed lag pattern, and neighbouring lag-basis coefficients should be similar for a fixed exposure-response pattern.
A convenient way to encode this was a Kronecker-sum precision matrix with separate smoothing strengths:
where \(Q_x\) and \(Q_\ell\) are second-order random-walk precision matrices along the exposure and lag bases. The first term penalised roughness along the lag direction within each exposure-basis block. The second term penalised roughness along the exposure direction within each lag-basis block. The two precision parameters allowed the fitted surface to be smoother in one direction than in the other, which was useful because exposure-response curvature and lag decay need not have the same scale.
rw_precision <-function(k, order =2) { D <-diff(Diagonal(k), differences = order)crossprod(D)}scale_rw2_precision <-function(Q) { k <-nrow(Q) constraints <-list(A =rbind(rep(1, k), seq_len(k)),e =c(0, 0) ) INLA::inla.scale.model(Q, constr = constraints)}rw_order_exposure <-2Lrw_order_lag <-2LQ_exposure <-scale_rw2_precision(rw_precision(k_exposure, order = rw_order_exposure))Q_lag <-scale_rw2_precision(rw_precision(k_lag, order = rw_order_lag))R_lag <-kronecker(Diagonal(k_exposure), Q_lag)R_exposure <-kronecker(Q_exposure, Diagonal(k_lag))Q_cross_display <- R_lag + R_exposurerankdef_cross <- rw_order_exposure * rw_order_lagimage(as.matrix(Q_cross_display), main ="Scaled tensor-product precision pattern")
The marginal RW2 precision matrices were scaled with INLA::inla.scale.model() before the tensor-product terms were formed. This made the two precision hyperparameters more directly comparable. The tensor-product precision was intrinsic: since each RW2 precision has a two-dimensional null space, the Kronecker-sum precision had rank deficiency \(2 \times 2 = 4\). This rank deficiency was passed to generic3 through rankdef.
Fit with inlabru
The important inlabru detail is the mapper. The component received A_cross, a sparse matrix with one row per observation and one column per latent coefficient. The mapper bm_matrix(ncol(A_cross)) told inlabru that this component should be evaluated by matrix multiplication.
mean sd 0.025quant 0.5quant
Precision for Cmatrix[[1]] for dlnm 449.5433 1059.8757 12.76912 176.0293
Precision for Cmatrix[[2]] for dlnm 445.2669 752.3627 22.60053 226.1602
0.975quant mode
Precision for Cmatrix[[1]] for dlnm 2613.487 29.76736
Precision for Cmatrix[[2]] for dlnm 2236.180 57.65692
Linear predictor and latent intensity
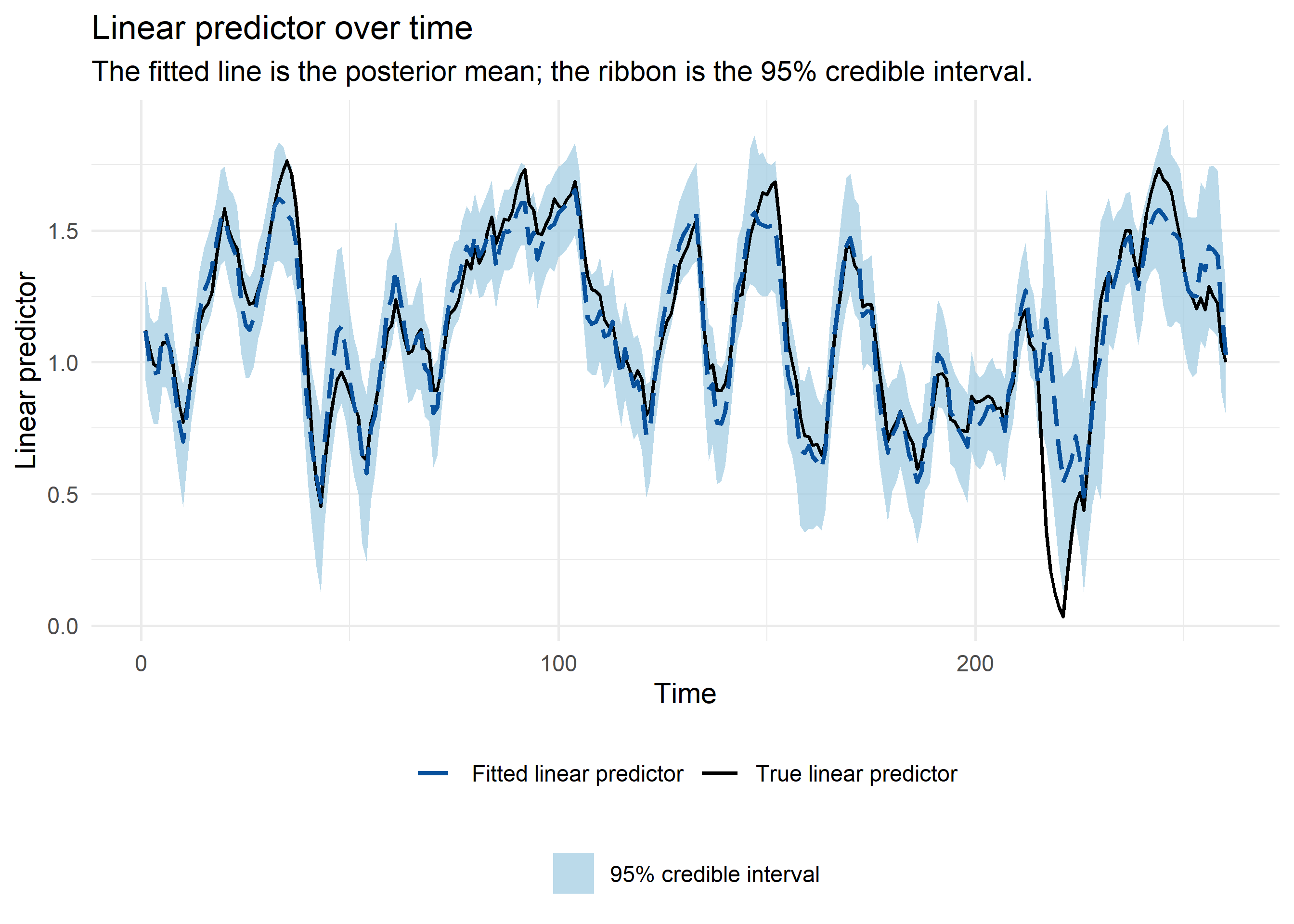
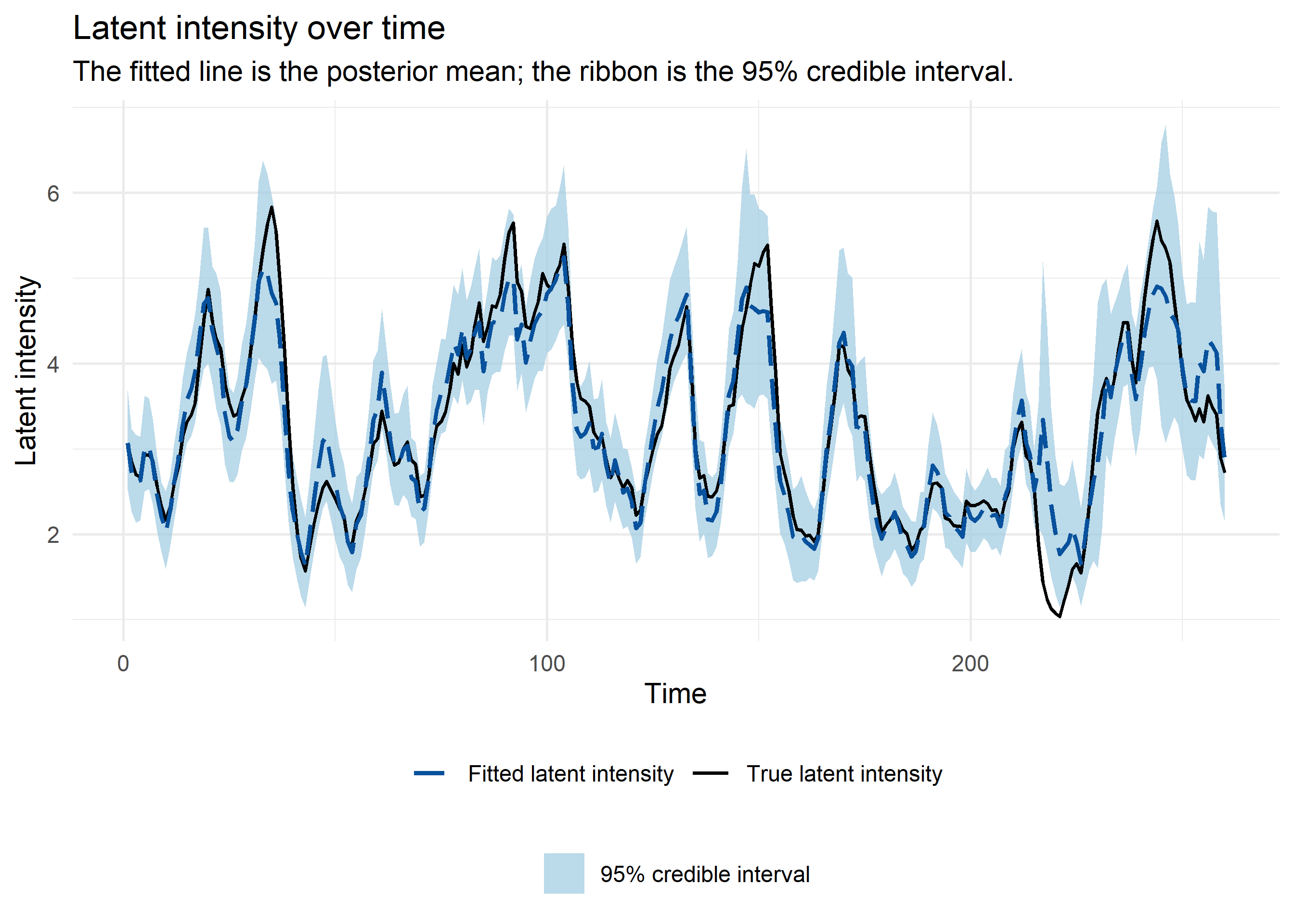
Because the data were simulated, the true linear predictor \(\eta_t = \alpha + \eta_{\mathrm{DLNM},t}\) and the true latent intensity \(\lambda_t = \exp(\eta_t)\) were known. This made it possible to compare the fitted linear predictor and fitted intensity directly with their simulated counterparts over time.
eta_prediction <-predict( fit_dlnm,formula =~data.frame(eta = Intercept + dlnm),n.samples =1000,seed =20260426)mu_prediction <-predict( fit_dlnm,formula =~data.frame(mu =exp(Intercept + dlnm)),n.samples =1000,seed =20260426)prediction_df <-data.frame(time =seq_along(y),eta_true = eta,eta_mean = eta_prediction$mean,eta_q025 = eta_prediction$q0.025,eta_q975 = eta_prediction$q0.975,mu_true =exp(eta),mu_mean = mu_prediction$mean,mu_q025 = mu_prediction$q0.025,mu_q975 = mu_prediction$q0.975)ggplot(prediction_df, aes(x = time)) +geom_ribbon(aes(ymin = eta_q025,ymax = eta_q975,fill ="95% credible interval" ),alpha =0.7 ) +geom_line(aes(y = eta_true,colour ="True linear predictor",linetype ="True linear predictor" ),linewidth =0.7 ) +geom_line(aes(y = eta_mean,colour ="Fitted linear predictor",linetype ="Fitted linear predictor" ),linewidth =0.85 ) +scale_colour_manual(values =c("True linear predictor"="black","Fitted linear predictor"="#08519c" ) ) +scale_linetype_manual(values =c("True linear predictor"="solid","Fitted linear predictor"="longdash" ) ) +scale_fill_manual(values =c("95% credible interval"="#9ecae1") ) +guides(fill =guide_legend(order =2),colour =guide_legend(order =1),linetype =guide_legend(order =1) ) +labs(x ="Time",y ="Linear predictor",colour =NULL,linetype =NULL,fill =NULL,title ="Linear predictor over time",subtitle ="The fitted line is the posterior mean; the ribbon is the 95% credible interval." ) +theme(legend.position ="bottom",legend.box ="vertical" )
In the linear-predictor plot, the true curve was mostly inside the 95% credible interval, apart from a short stretch after time 200. That departure occurred where the latent intensity was low. On the observation scale, this produced many zeros and ones, which made the depth and timing of the trough weakly identified.
The latent-intensity plot is a useful simulation check, but it is not a posterior predictive check. The model was fitted to one noisy Poisson count at each time point, not to the black latent-intensity curve. Local departures between the fitted line and the simulated truth can therefore occur even when the DLNM structure is appropriate. The posterior predictive check below added the Poisson observation layer back in.
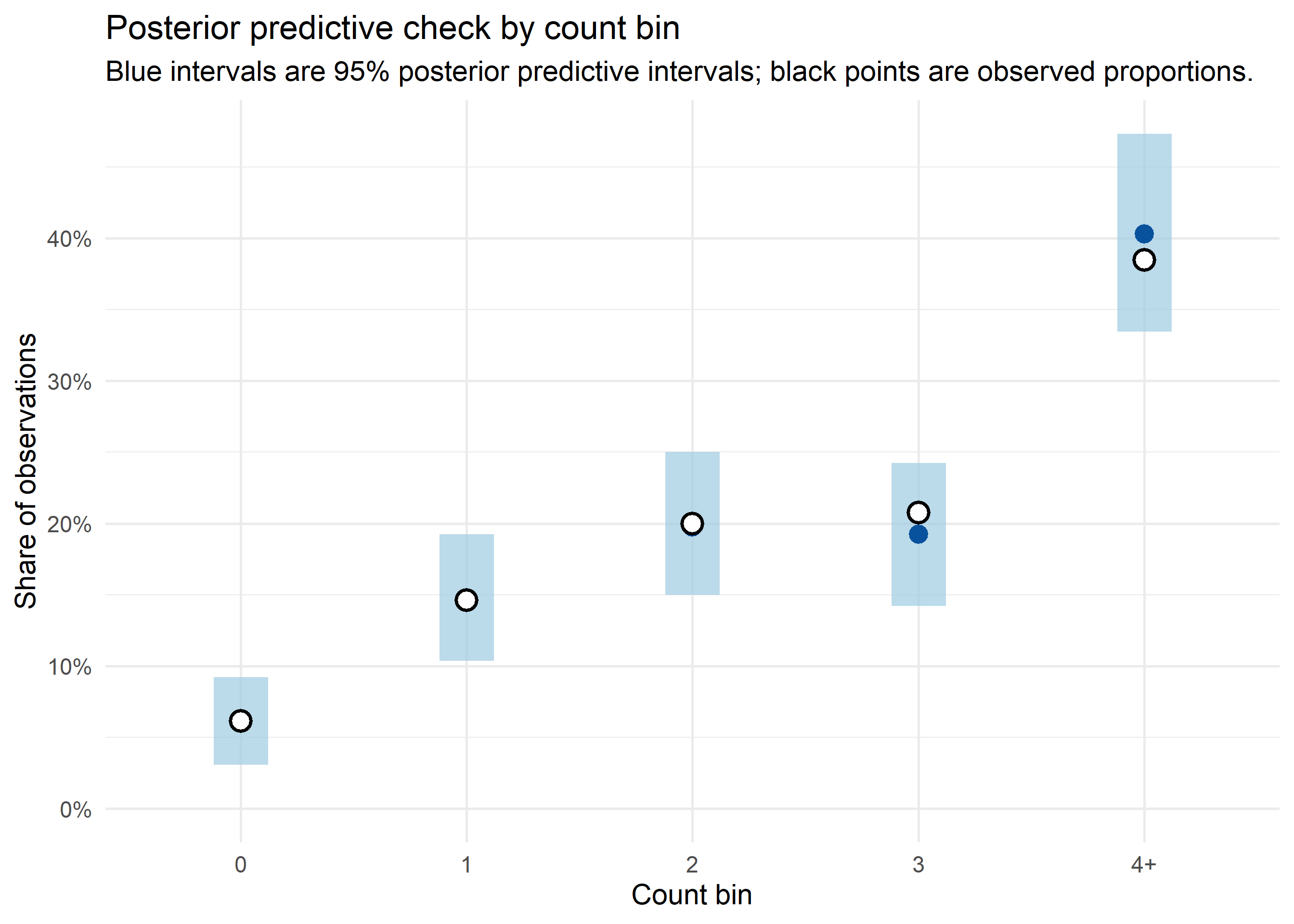
Posterior predictive check
For the posterior predictive check, I added the observation noise back in. The predict() call below sampled the latent mean \(\mu_t = \exp(\alpha + A_t\theta)\), rpois() drew replicated counts from the Poisson observation model, and the result was reduced to count-bin proportions. This checked whether the fitted model reproduced the discrete distribution of the observed response, rather than only the latent mean.
To reconstruct the fitted surface, I evaluated the DLNM component on a regular exposure-lag grid. I subtracted the fitted effect at the reference exposure \(x = 0\) on the linear-predictor scale, then exponentiated the result. The plotted surface was therefore a lag-specific relative effect.
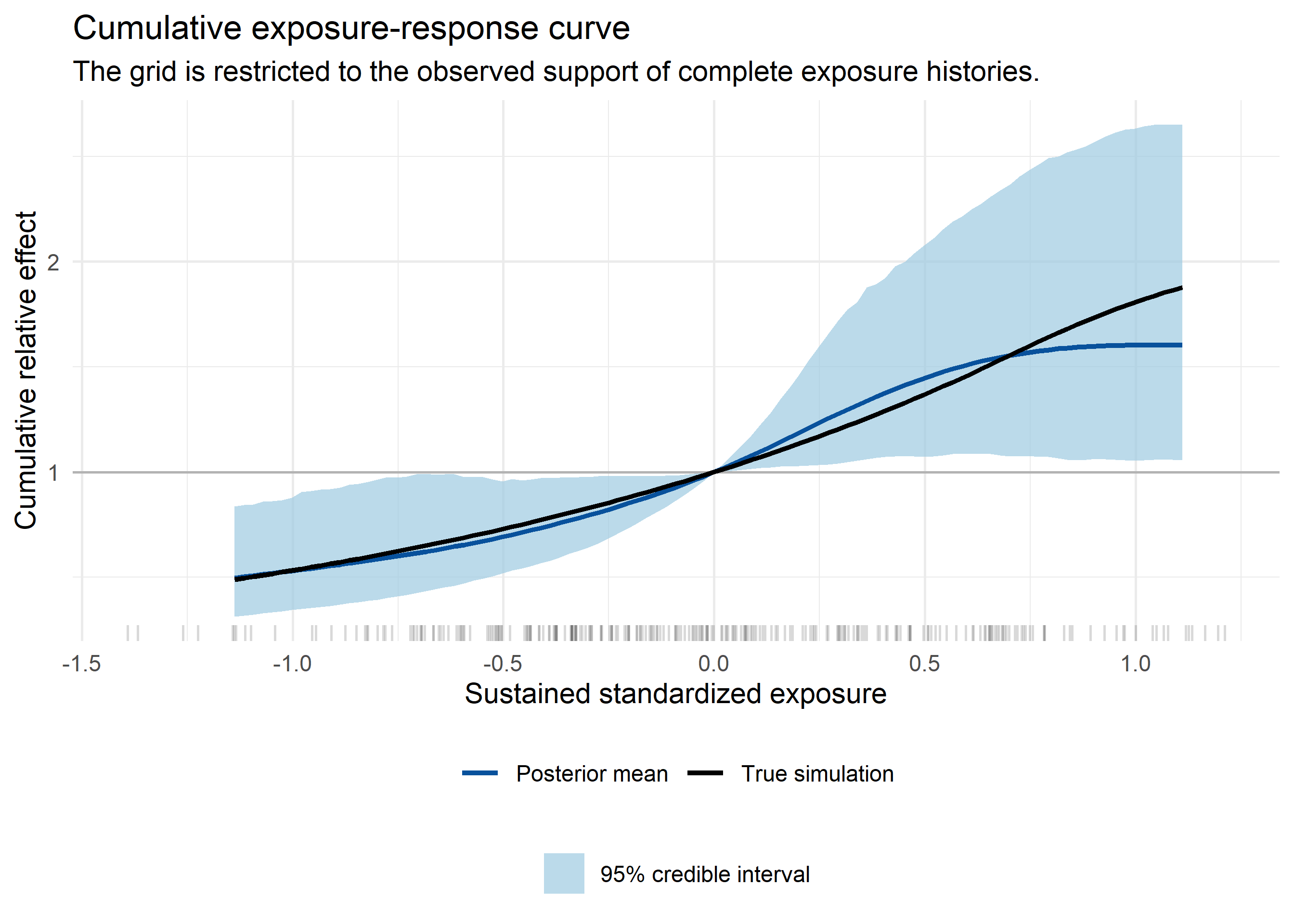
A cumulative exposure-response curve was obtained by summing the lag-specific effects over \(\ell = 0,\ldots,L\) on the linear-predictor scale and then exponentiating. In this example, it answered a concrete question: what total relative effect would we get if the same standardized exposure value were sustained throughout the whole lag window? A negative sustained exposure meant a below-average standardized exposure held constant over all lags.
For this curve, I used a more conservative exposure grid than in the surface plot. The surface plot used the marginal range of all lagged exposures, but a sustained exposure is a full exposure history. Asking for all lags to be held at a marginal tail value would extrapolate beyond the histories that were actually observed. I therefore based the cumulative grid on the central range of the row-wise mean exposure history.
This construction was deliberately explicit. In a real analysis, I would add the usual time-series structure around the DLNM term: seasonal terms, long-term trend, calendar effects, overdispersion if the Poisson variance is too small, and possibly autocorrelated residual structure. The cross-basis term is only one part of the linear predictor.
The main technical point was simple: once the exposure histories had been converted into a cross-basis matrix, the DLNM became a linear model component. From there, inlabru could fit it as a latent Gaussian component, with the prior structure controlled through the list of precision matrices passed to generic3.
An alternative to generic3 is generic0, which uses a single precision parameter for the whole combined penalty matrix. In the notation used above, this corresponds to replacing the two-precision structure
\[
\tau_\ell R_\ell + \tau_x R_x
\]
with the simpler one-precision structure
\[
\tau (R_\ell + R_x).
\]
In settings with substantial uncertainty, as in this small simulated example, that simpler latent effect can be preferable because it reduces the number of smoothing hyperparameters that must be learned from the data. I used generic3 here because it is more general and makes the exposure-direction and lag-direction regularisation explicit.